My research focuses on learning robust visual models under imperfect supervision, particularly for object detection and semantic segmentation. In real-world settings, visual datasets are often noisy, incomplete, imbalanced, or drawn from multiple sources with differing annotation schemes. I study how vision systems can be trained effectively under these conditions, where both data quality and domain shift present significant challenges.
A central theme of my work is exploring the interplay between model-centric and data-centric approaches to domain adaptation. On the model side, I develop learning strategies that improve robustness to domain shift and class imbalance. On the data side, I investigate methods for aligning and unifying heterogeneous datasets, enabling models to learn from diverse sources despite inconsistencies in labels, distributions, and annotation standards.
More recently, I have become interested in the role of generative synthetic data and emerging world models as tools for improving visual learning. By generating controllable training environments and augmenting datasets with structured synthetic data, these approaches offer new opportunities to study generalization and robustness in vision systems operating under distribution shift.

Label Transfer from multiple source object detection datasets to a target label space. Code soon to be released.
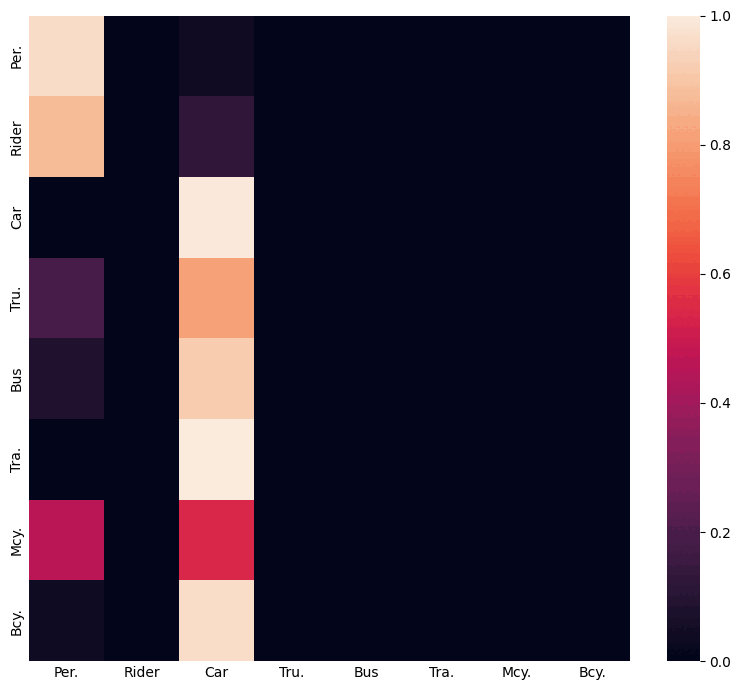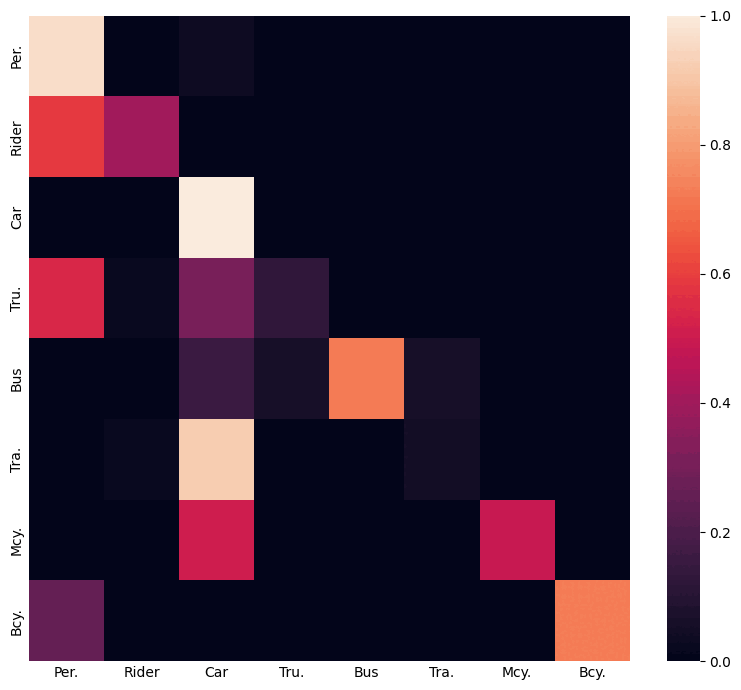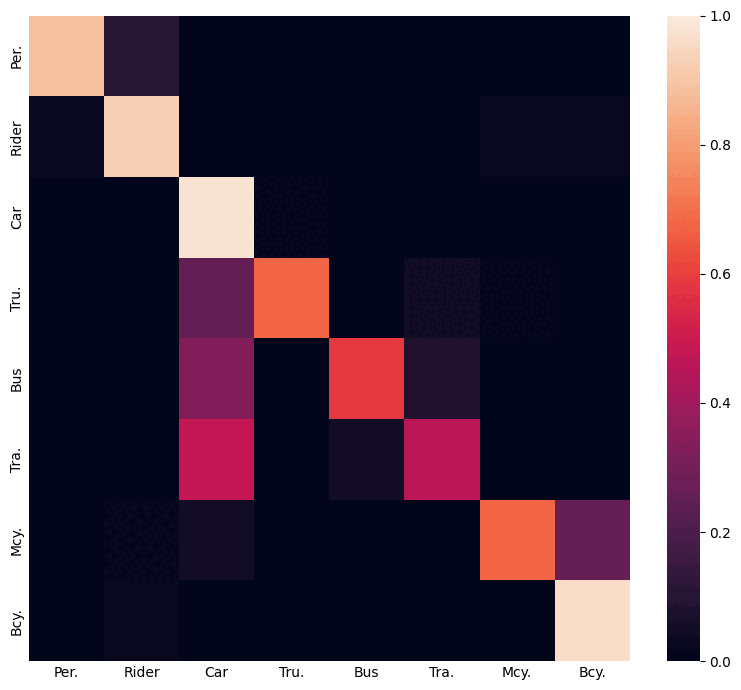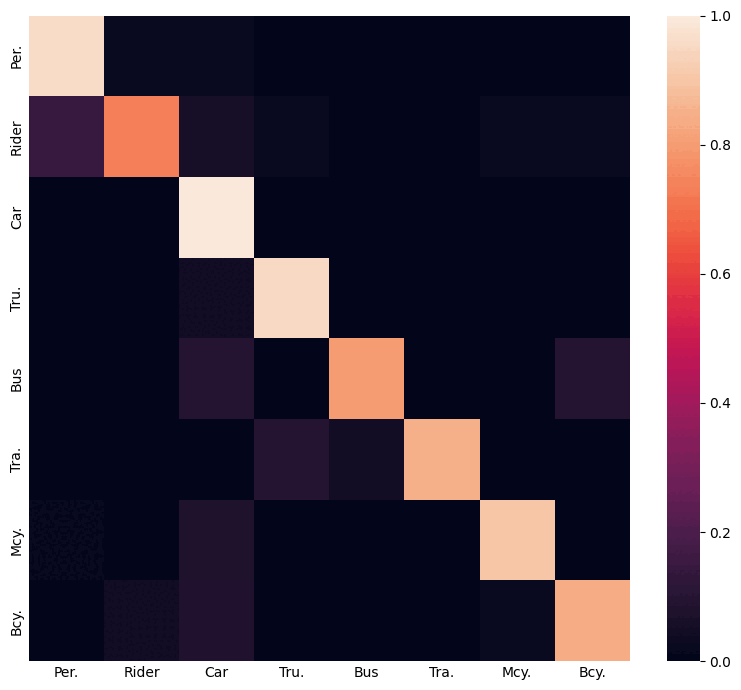
Using inter-class relations to address the class-imbalance problem in domain adaptive object detection.
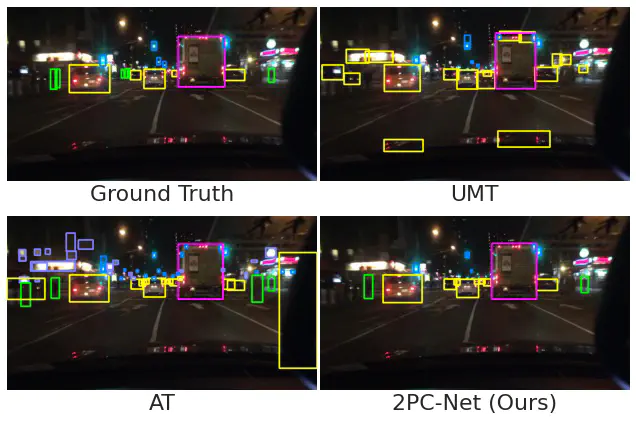
Utilising low-confidence samples in the student-teacher network to learn more of the target domain.